One of the tenets of first normal form database design is to only allow atomic values in a column. However, that is not always the case in the real world.
I recently encountered a multi-valued column on a project and instead of writing a bunch of OR and SUBSTR(right of =) functions, I saw a pattern and used the FIND() [CHARINDEX() in SQL Server] and MOD() [% in SQL Server] functions. The use of the FIND() and MOD() functions was not only easier to maintain (less lines of code) but ran about twice as fast.
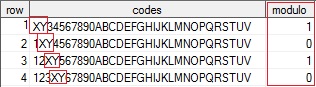
The below code emulates a multi-valued column populated via the SUBSTR(left of) to stuff the 'XY' values in the multi-valued column. The requirement is to find the value 'XY' only on an odd numbered positions (e.g. 1, 3, 5, etc). The FIND() function returns the starting point of the searched string and then the MOD function is used to determine if that position is an odd or even starting location. Modulo finds the remainder after division of one number by another. From Wikipedia:
Given two positive numbers, a (the dividend) and n (the divisor), a modulo n (abbreviated as a mod n) is the remainder of the Euclidean division of a by n. For instance, the expression "5 mod 2" would evaluate to 1 because 5 divided by 2 leaves a quotient of 2 and a remainder of 1, while "9 mod 3" would evaluate to 0 because the division of 9 by 3 has a quotient of 3 and leaves a remainder of 0; there is nothing to subtract from 9 after multiplying 3 times 3.
In order to really see the performance differences in these approaches, I wrote a macro to create a million row SAS data set. After that, the two techniques were bench-marked. The FIND()/MOD() technique took 0.35 seconds vs 0.68 seconds using OR and SUBSTR().
data test( keep = row codes ) ; length row 3 codes $32 ; do row = 1 to 31 ; codes = '1234567890ABCDEFGHIJKLMNOPQRSTUV'; substr( codes, row, 2 ) = 'XY' ; output ; end ; run ; %macro loopdata ; %local setnotes loopdataset ; %let setnotes = %sysfunc( getoption( notes ) ) ; %let loopdataset = %sysfunc(ceil( %sysevalf( 1000000 / 31 ) ) ) ; options nonotes ; /* turn off notes to the SAS log */ data testlarge ; set /* create a millon row data set */ %do i = 1 %to &loopdataset. ; test %end ; ; run ; options &setnotes ; /* reset NOTES to previous value */ %mend ; %loopdata proc sql stimer ; create table sqlmod as select row , codes , case when mod( find( codes, 'XY', 'i' ), 2 ) then 1 else 0 end as modulo from testlarge ; create table sqlsubstr as select row , codes , case when substr( codes, 1, 2 ) = 'XY' or substr( codes, 3, 2 ) = 'XY' or substr( codes, 5, 2 ) = 'XY' or substr( codes, 7, 2 ) = 'XY' or substr( codes, 9, 2 ) = 'XY' or substr( codes, 11, 2 ) = 'XY' or substr( codes, 13, 2 ) = 'XY' or substr( codes, 15, 2 ) = 'XY' or substr( codes, 17, 2 ) = 'XY' or substr( codes, 19, 2 ) = 'XY' or substr( codes, 21, 2 ) = 'XY' or substr( codes, 23, 2 ) = 'XY' or substr( codes, 25, 2 ) = 'XY' or substr( codes, 27, 2 ) = 'XY' or substr( codes, 29, 2 ) = 'XY' or substr( codes, 31, 2 ) = 'XY' then 1 else 0 end as modulo from testlarge ; quit ;
Hi Tom, have you tried with the index functions.
ReplyDeletedata test1;
set test;
if index(codes,'XY') in (1,3,5,7,9, etc) then modulo=1;
else modulo=0;
run;
The use of the INDEX() / IN() is an alternative but is slower than the FINDI()/MOD() approach and you are forced to enter the IN() list of values. The MOD() function does not require a list of values so it is again faster, more elegant and easier to maintain.
ReplyDelete